新闻列表
哈工大自然语言处理研究所成功举办2026年ACL预讲会

为推动所内学术交流,营造活跃的科研氛围,哈尔滨工业大学自然语言处理研究所(HIT-NLP)于2026年4月19日成功举办2026年ACL线上预讲会。
哈工大自然语言处理研究所发布《2025年大语言模型进展报告》

2025年,大语言模型领域的技术创新与应用探索持续加速。2025年,大语言模型领域的技术创新与应用探索持续加速。从年初DeepSeek-R1引发广泛关注,到年末Gemini 3 Pro在多项基准上取得领先,模型架构、训练范式、推理能力、应用场景均呈现出深刻变革。为系统梳理2025年大语言模型的关键进展与趋势走向,哈尔滨工业大学自然语言处理研究所组织数十位教师与研究生,编撰完成了《2025年大语言模型进展报告》。
哈工大自然语言处理研究所发布《2025年大语言模型进展报告》
2025年,大语言模型领域的技术创新与应用探索持续加速。2025年,大语言模型领域的技术创新与应用探索持续加速。从年初DeepSeek-R1引发广泛关注,到年末Gemini 3 Pro在多项基准上取得领先,模型架构、训练范式、推理能力、应用场景均呈现出深刻变革。为系统梳理2025年大语言模型的关键进展与趋势走向,哈尔滨工业大学自然语言处理研究所组织数十位教师与研究生,编撰完成了《2025年大语言模型进展报告》。哈工大 SCIR 多篇长文被 ACL 2026 主会/Findings 录用

ACL 2026 将于 2026 年 7 月 2 日至 7 月 7 日在美国加利福尼亚州圣迭戈举行。ACL 年会是计算语言学和自然语言处理领域最重要的顶级国际会议,由计算语言学协会主办,每年举办一次。其接收的论文覆盖了对话交互系统、语义分析、摘要生成、信息抽取、问答系统、文本挖掘、机器翻译、语篇语用学、情感分析和意见挖掘、社会计算等自然语言处理领域众多研究方向。
哈工大 SCIR 多篇长文被 ACL 2026 主会/Findings 录用
ACL 2026 将于 2026 年 7 月 2 日至 7 月 7 日在美国加利福尼亚州圣迭戈举行。ACL 年会是计算语言学和自然语言处理领域最重要的顶级国际会议,由计算语言学协会主办,每年举办一次。其接收的论文覆盖了对话交互系统、语义分析、摘要生成、信息抽取、问答系统、文本挖掘、机器翻译、语篇语用学、情感分析和意见挖掘、社会计算等自然语言处理领域众多研究方向。ICLR 2026 | 2% is enough:用最少的代码,做最精准的测试样例评估

大模型代码能力评估和代码强化学习基于测试用例来提供正确性。然而,人工编写的黄金测试用例稀缺且昂贵,由 LLM 自动生成的测试用例质量又缺乏科学的衡量标准——现有评估方法要么依赖海量错误代码暴力比对,计算成本高昂且分数严重膨胀;要么启发式采样...
ICLR 2026 | 2% is enough:用最少的代码,做最精准的测试样例评估
大模型代码能力评估和代码强化学习基于测试用例来提供正确性。然而,人工编写的黄金测试用例稀缺且昂贵,由 LLM 自动生成的测试用例质量又缺乏科学的衡量标准——现有评估方法要么依赖海量错误代码暴力比对,计算成本高昂且分数严重膨胀;要么启发式采样...ICLR 2026 | ProxyAttn让代理注意力头“划重点”,免训练实现无损稀疏

现有稀疏注意力方法多在“序列维度”压缩,容易丢失关键信息。ProxyAttn 另辟蹊径,利用长文本下注意力头表现趋同的特性,在“Head维度”进行压缩。通过一个“代理头(Proxy Head)”来预估重要性,实现了精度与速度的帕累托最优。
ICLR 2026 | ProxyAttn让代理注意力头“划重点”,免训练实现无损稀疏
现有稀疏注意力方法多在“序列维度”压缩,容易丢失关键信息。ProxyAttn 另辟蹊径,利用长文本下注意力头表现趋同的特性,在“Head维度”进行压缩。通过一个“代理头(Proxy Head)”来预估重要性,实现了精度与速度的帕累托最优。思维链的“脆性”真相:哈工大赛尔ICLR 2026论文揭示输入扰动对推理的影响

思维链技术(Chain-of-Thought, CoT)是一种有效增强大语言模型(Large Language Model, LLM)推理性能的方法。通过要求模型在生成答案的同时提供推理过程,来引导模型更深入地思考问题并探索不同的推理思路,...
思维链的“脆性”真相:哈工大赛尔ICLR 2026论文揭示输入扰动对推理的影响
思维链技术(Chain-of-Thought, CoT)是一种有效增强大语言模型(Large Language Model, LLM)推理性能的方法。通过要求模型在生成答案的同时提供推理过程,来引导模型更深入地思考问题并探索不同的推理思路,...喜讯 | HFL荣获2025年度IEEE信号处理学会最佳论文奖

近日,电气电子工程师协会(IEEE)信号处理学会(IEEE Signal Processing Society)公布了2025年度各类奖项名单。HFL实验室研究团队荣获IEEE信号处理学会最佳论文奖(IEEE SPS Best Paper ...
喜讯 | HFL荣获2025年度IEEE信号处理学会最佳论文奖
近日,电气电子工程师协会(IEEE)信号处理学会(IEEE Signal Processing Society)公布了2025年度各类奖项名单。HFL实验室研究团队荣获IEEE信号处理学会最佳论文奖(IEEE SPS Best Paper ...哈工大 SCIR 2025 年终总结会成功举办

2025 年 12 月 27 日下午,哈工大社会计算与交互机器人研究中心举办了 2025 年终总结会,共同迎接新一年的到来。
哈工大 SCIR 2025 年终总结会成功举办
2025 年 12 月 27 日下午,哈工大社会计算与交互机器人研究中心举办了 2025 年终总结会,共同迎接新一年的到来。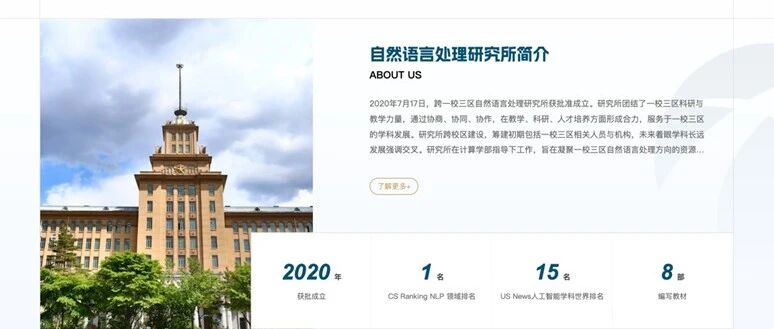
赛尔笔记|架起感知到行动的桥梁 - 具身智能中的CoT技术概述

本文全面回顾了近期具身CoT方法。近期研究主要围绕推理中间数据表征设计,训练以及推理优化展开。